
I’m sure some senior engineers I highly respect are gnashing their teeth and frothing at the bit to give me a piece of mind just reading that headline.
Sorry. I’ll do my best to defend that preposterous title, and am fully aware that the ‘LeetCode grind’ is pretty miserable for most people. (That said, since I’m self-taught you can expect me to be at least a little biased here.)
I swear I’m going to (try to) make a non-trivial point here, which is basically just that as a process algorithmic interviews are completely fine. What makes them such a pain point—especially for senior engineers looking to switch jobs—is a deeper, impossible-to-avoid problem: It’s fucking hard to measure engineering skills in a hyper competitive environment.
Also, that the shift from ‘unstructured’ hiring towards a formalized interview process was essentially inevitable. (Whether this is a good thing or the inevitable march of tyranny and bureaucracy is for other people to decide.)
Really, I’m primarily trying to gather my thoughts, so this article will be a bit rambly. What I’m grasping at in this post is that the LeetCode interview is (essentially) an example of how social processes standardize, and I’m trying to work out a framework for how to even talk about this.
This is especially interesting since we live in a digital world, full of technology capable of facilitating the standardization of social processes.
Seeing Like a State
In the following I’ll probably throw around the words ‘metis’ and ’episteme’, lifted out of James C. Scott’s Seeing Like a State.
Episteme is something like formalized top-down knowledge (e.g. maps), metis is local knowledge that’s hard to write down (e.g. your gut-feeling telling you that one of your chickens seems unwell).
Scott examines history through the lens of ’legibility’, and describes how states needed to create maps and identifiers (e.g. surnames, street names) to achieve their goals. It doesn’t matter whether the goal is to tax, oppress, uplift, or to provide healthcare, you cannot do it without a top-down map of the landscape, the people, and the names.
Beyond that, the book is about how exactly this ’epistemic’ top-down view frequently ends up being ignorant of the social complexities and ’lived reality’ of the people it claims to represent, or of what these people actually care about.
In fact, ignorance is putting it mildly. In practice, local social rules and interests are brushed aside and overrided in accordance to a beautiful, grand plan that looks beautiful on paper, and then ends up making everyone miserable. (That’s a simplification of what Scott is saying, but you get the idea.)
One of Scott’s favorite examples is that of modernist planned cities, which looked amazing as a model, but sucked absolute ass to live in.
Most specifically, the type where ‘brilliant architects’ conceive of a massive, revolutionary plan that starts by bulldozing everything that’s already there to create a ‘perfect’ uniform landscape, and ends with an even number of monstrous concrete skyscrapers, all arranged in a perfect rectangular grid and completely indistinguishable from one another.
Needless to say, Le Corbusier’s plans were controversial at best:

Even in the best cases they had a habit of fully separating parts of the city according to their responsibilities, or in other words, were vehemently opposed to the idea of cafes and corner shops mingling with apartments. The idea of people wanting to ’take a walk’ and spontaneously grabbing a drink in a local cafe was pretty much entirely foreign to him.
Seeing Like a State is an academic doorstopper with a higher ratio of pages-to-footnotes than my blog, and frankly, I don’t want to retread old ground by repeating what other people have already said better than I ever could. If you’d like to take a look, there are better places to start than the book itself, honestly.
James C. Scott’s wrote a summary of his own. Scott Alexander has a great book review, and so does Venkatesh Rao. Finally, Lou Keep’s ‘Man as a Rationalist Animal’ holds a special place in my heart, and I consider his whole series to be one of the best I’ve ever read.
Anyway.
I don’t have a smooth transition into the rest of the article. Seeing Like a State gave me a lot to think about. That’s all.
It raises a lot of questions about how the legibility of data and processes shift power dynamics within society.
This is especially important in an increasingly digital world, in which the minor technical details of technical protocols can have a significant impact. For example, e-mail. E-mails are everywhere. This sounds like a trite point, until you realize that the protocol is decades old, and that existing corporations are forced to work around it due to its momentum. (As opposed to, y’know, getting to lock you into a specific corporate protocol.)
In other words, the exact details of a specific technical protocol had a massive impact on modern society.
Likewise, the exact specification of ActivityPub will impact its ability to reach its goal of shifting power away from corporate-owned social networks towards decentralized ones.
The flipside of all of this is that it makes sense to look at less-technical-more-social processes or standards, and to see how social patterns imprint themselves on technical protocols. (Example: The concept of ‘followers’.)
This also includes the standard technical interview process.
Processes
A social process1 codifies how metis (raw human input, emotions, wants, gut feeling, tacit knowledge, the social environment) is aggregated and converted into episteme (data, action items, formalized consensus, certificates, top-level decisions, knowledge).
If you’re partaking in a ‘process’ that involves professional managers and you cannot figure out what the ’epistemic goal’ (e.g. action items, formalized consensus) of the whole procedure is, then that’s a tell that you’re either out of your depth, or that the process is not functioning particularly well.
Example: A manager from a client team might be pulling you and your product manager into a sync, with the specific goal of getting a concrete go-ahead on “Is this thing you’re working on going to meet our requirements, and is it going to be ready at date X?” Based on your answer, they’ll then plan around that (or not).
Your domain-knowledge, gut feeling, ability to understand the requirements, etc. are what go in, and what comes out is a (hopefully concrete) “Yes, this should be ready by date X.”
Communication skills are one of the most critical skills in a corporate environment. If for nothing else, then just to prevent misunderstandings when talking to people who’re only tangentially familiar with your work, use a completely different language, and only have a few minutes to spare.
I don’t have a lot of experience here, but as far as I can tell this becomes increasingly more pronounced as you walk up the corporate ladder.
A few steps above the common Joe, you’ll find so-called VPs and GMs whose primary purpose is to sit in rapid-fire 30 minute meetings, and to make a highly business critical decision in every single one of them.
This job is not exactly about having deep technical insights and coming up with a solution, no.
If you’re in this position, your job is to have solutions presented to you, and to make ‘Yes/No’ calls based on your gut feeling, your confidence in the people presenting them, and based on whether it looks as if the involved parties have already found an agreement without your input ahead of time.
In return, your reports get to parade your name around on a stick and say that their solution has ’leadership buy-in’, which helps when figuring out who needs to drop other work to help them make it happen.
It’s easy to see where this entire process can go wrong. You don’t have as much technical knowledge as your reports (for the obvious reasons), and most of your data gets filtered through your reports. In other words, if one of them has a wrong understanding of the world and presents you bad solutions, there’s a good chance you’re not in a position to tell the difference.
The details here are out of scope of this article2, all what I’m saying is that there’s a ‘process’ at play here where ’leadership’ has to deal with a firehose worth of raw information, know how to read between the lines and juggle various implicit factors, and then turn that into clear, actionable decisions.
There are a lot more things that I’d classify as processes:
- A doctor diagnosing a patient is an example of a process which utilizes the tacit knowledge of the doctor, with the goal of converting it into an easily communicated set of precise symptoms and a (socially legitimate!!!) root cause.
- The point of a knowledge transfer is to ensure that the ’new people’ can fill in for the original team. From a high-level perspective, you don’t care about the details. All you care about is that, once it is completed, the new team will be able to pick up the work of the old team without problems (whatever it is).
- Surveys. Even incredibly basic ones, such as upvotes on a YouTube video. From a principled perspective, a survey can be used to make a pass/fail decision for a feature or idea. Either people like it, and you double down in that direction, or they don’t. It’s all about aggregating vast amounts of ‘raw human input’, and converting it into a few simple numbers, as a proxy for quality or engagement.
- (The process of obtaining a) driver’s licence. The whole point of a licence (of any type) is that it allows you to carry a piece of formalized social consensus with you, certifying your ability or right to do something. This significantly simplifies communications, and allows a formalization of the entire process surrounding it. (For better or for worse.) Big surprise, this is also the predominant role of higher education.
- Ticket systems, task tracking systems are all about quantifying the importance of work items (with associated metadata), and having some source of truth which the team agrees on. “Which work should be done?” is an incredibly hard question, whereas “Which item has a higher priority on the stackrank?” is easy to answer. Sadly, I’m not aware of reliable methods for keeping the system in sync with the team’s current understanding of the world.
- Dating. Dating is a process that aims to turn the vague, diffuse interests of two people into an “actual relationship”. (This is a horrible simplification, and also makes it sound like about the most joyless thing ever. Go figure.)
- Democracy, or any sort of voting process is about—look, you can figure this one out for yourself.
And so on, and so on, and so on.
It shouldn’t be much of a surprise that I believe the exact same framework can be applied to the standard ‘Algorithms and Data Structures’ interview.
Algorithmics, data structures, interviews
As a first approximation, the point of the algorithmics interview is to figure out if someone would make for a good engineer.
Taking a slightly closer look, this is still true, but the ‘constraints’ of this solution become more obvious. It’s not just about finding good engineers, it’s about having a standardized, ordered process amenable to top-level aggregation and inspection.
class Solution: # https://leetcode.com/problems/powx-n/description/
def myPow(self, x: float, n: int) -> float:
return x ** n # 💪😤
The idea is simple, you want to hire great programmers, so you give all candidates technical questions
(e.g. “Given a list of numbers, how would you go about finding the N-th largest number?”) and
have them implement an algorithm that solves the problem. The interviewer then evaluates their performance
and rates them, either according to some sort of rubric, or with a simple pass/fail decision.
Sounds simple enough, right? It makes sense!
How else would you suss out if someone would make for a great candidate, other than by testing their abilities?
Most senior engineers I know speak with nothing but disgust of this style of interview. If not disgust then weariness. Perhaps they’re unhappy with their current job, but weary at the prospect of having to go through ’the leetcode racket’ again to land something better.
The reality is that your ability to solve algorithmic challenges does not correlate particularly well with the skills needed to be a good engineer. Not beyond a certain point, anyway. Yes, it’s a good filter for ‘very basic coding skills’, g-factor, dilgence and whether someone has basic conversational skills, but that’s about it.
In practice, senior software engineers exist to worry about much harder problems than basic algorithmics. They’ll rightfully be annoyed if they get sent ‘back to the LeetCode grind’ just to get past their next FAANG interview. Senior engineers don’t exist to solve algorithmics problems. They solve “Why is everything so fucked up?"-style problems across a massive codebase.
You might think that senior engineers exist to deliver big features, but in practice, there’s often a “Why is everything so fucked up?"-style problem hiding just below the surface that explains why the feature has been hard to deliver so far.
The reason why we (or ’leadership’) doesn’t think of them that way is that it’s much easier to communicate someone’s ‘value’ in terms of legible data, e.g. profit, user count, specific delivered features.

So, why algorithmics? Simple.
Performance at algorithmics is easy to measure
LeetCode-style interviews exist because performance at algorithmics is easy to measure.
Slightly more abstractly:
The design of processes is informed by ease of encodability.
Everyone would prefer to measure your long-term problem solving skills, your ability to pick up new knowledge over the span of a few weeks, how careful, diligent or hard-working you are in a honest work environment, or just your ’team fit’, all of which are basically impossible to measure without investing a significant amount of time (and requiring the same investment from you).
There’s another obvious point here, which is that any digital approximation of the real world is intrinsically going to be incorrect. No matter how hard you try, the map is not the territory. Any attempt to encode data loses something. Or to use someone else’s words, programming is forgetting.
In practice, this means that any attempt to measure your ability to perform at a job (or increase shareholder value, or whatever) is going to be flawed. That’s not a big deal, and it’s a pretty trivial observation, but it’s still important to remember.
My stance here is that that the algorithmics interview is—as far as processes go—reasonably well-designed. All of its problems are the consequence of a competitive market environment (+ difficulties with measuring anything else) and not issues with the process itself.
Let me repeat that: It’s really important to understand that a process can be ‘bad’ and ‘frustrating’ and ‘oh fuck i do not want to deal with this’ not because it’s ‘poorly designed’, but because it’s intrinsically hard to measure the correct data, especially in a competitive or adversarial environment.
As Goodhart’s Law starts to take hold (“Any measure which becomes a target becomes a bad measure.”), you can make the point that the process needs to be ‘dynamic’ or ‘obscure’ enough to avoid Goodhart’s law. This is what we’d usually call ‘Security by Obscurity’, but there’s probably no way around it. If the interviewee knew in advance which problems are going to be on the test, it’d be hard to test their problem solving skills.
Despite it being a mess, I still call it ‘well-designed’:
- For the interviewer, the process is clearly time-boxed. It’s also dead simple, cheap, and doesn’t require a lot of preparation or training (from the interviewer, anyway).
- In particular, the time investment that’s strictly necessary is minimal. If you take issue with that due to ‘having to practice algorithms for weeks for your interviews’, I’ll refer to the fact that this is due to the highly competitive environment. You still have control over how much you practice.
- The types of problems are known in advance, and the expectations are clear for everyone who’s involved. This allows the interviewee to know how to prepare for it, and there is less risk of being blindsided.
- It allows sidestepping other (exclusionary, less useful) signals for junior engineers who’re entering the market. No credentialism. No money needs to be paid to prepare for this.
- It provides a very clear, easy to describe ‘minimal bar’. Everyone who works here has demonstrated that they know what a hash map is and how recursion works.
- Due to the time-boxed and collaborative nature, it’s basically impossible for the interviewer to skimp out on it: They have to be there for the interview, for the full timeslot. This avoids failure modes where your engineer has control over how much time they put into the performance evaluation. (For example, you might take an intern, but the person responsible for keeping track of how well they’re doing is too busy to take their duties seriously.)
- Finally, it allows further standardization of the hiring process.
Does this mean the process works amazingly well in practice? Well, clearly not. But again—this is the most important part, so pay attention—the process itself is well-designed, it’s just incredibly hard to do better than this in a highly competitive environment.
The same is true even in a world in which people will relentlessly try to cheat during their interviews: That’s not exactly an issue with the process (as defined by social expectations and the transformation of raw human judgement into a clear set of data), that’s a technical issue. And this type of technical issue can (at worst) be solved by doing interviews in person.
There are alternatives to all of this: You can just allow your employees to do their interviews however they want (might work in small places), you can reject all candidates without a Master’s degree in Computer Science and just do a ‘culture fit’ check for those (a terrible idea for all sorts of reasons), or you can relax hiring practices, overhire and then just fire employees who’ve not ’exceeded expectations’ within the first year3.
You might say “Well, just keep the process and do interviews that aren’t pure algorithmics!”
Which, fair enough! The reality is that people are already doing that. There are domain-knowledge interviews, and they can be completely fine. Likewise, sure, ‘system design’ interviews are a whole thing that exists. Technically not ‘algorithms’, but still in the same ballpark. I am not objecting to either of these, and put them in the same category of ‘reasonably well-designed process’ (assuming that you’re following some basic rules).
In fact, let me make one thing clear: The point that I’m trying to make here isn’t that the ‘Algorithmics Interview™’ is clearly better than other forms of selection processes.
The point I am making is that society (if you will) has a habit of gravitating towards legible, standardized processes and patterns. Insofar as it was inevitable for society to drift towards a ‘standard’ for big tech job interview processes, the algorithmics interview is honestly pretty decent.
Organisations tend to gravitate towards legible, standardized processes

The title of this section should make you pause, considering that I went on a whole tangent about how leadership is (by nature) incapable of making nuanced technical decisions, and primarily exists to delegate authority, decide ‘values’ and break ties between groups.
Anyway.
That doesn’t stop it from being true. The way it looks to me is that—very roughly speaking—society will naturally gravitate towards standardization, as long as there’s no significant gain be had from diverging. This has technical and social reasons. If you’re already familiar with how a certain process work, you’ll follow the same patterns in similar-looking situations.4
For example, a large number of advances in practical computer science can be interpreted as taking literally anything at all, making it measurable, and developing legible, standardized protocols around it. Why? Well, at the very least it’s going to save you some work to align with others, instead of having to reinvent the wheel!
Some of these protocols are protocols (or data formats) in the most literal sense (JSON, C ABI, HTTPS, etc.), some are less standardized and they exist in many different forms (upvotes, user profiles, accounts, passwords, replies, etc.).
Likewise, a large number of advances in finance can be interpreted as taking literally anything at all, and making it fungible. Commodities (crude oil, copper, onions, live hogs) can be traded, but so can abstract legal claims to corporate entities, debt, “the option to buy something in the future at a specified price”, and other things. Commodity futures are my favorite example, just for how straightforward they are.5
In other words, standardization happens all the time, everywhere.
By the same logic, of course society will slowly standardize towards certain ways of gating access to jobs.
Of course these patterns of standardization (of technical protocols, contracts, securities, etc.) are also going to apply to bog-standard bureaucratic office processes.
From the perspective of corporate organisation, anything but a process that’s easy to aggregate data over, easy to inspect, easy to regulate was always a non-starter.
Such a process doesn’t have to look like a standard algorithmics interview. It could be a take-home exercise6. It could, for example, also come in the form of a formal internship. It could come in the form of external institutions that vet people or judge them by their abilities. It could involve a background check for credentials and risks.
In reality, we’re using a combination of all of these. The one thing that we’re not doing is moving towards an unprincipled “Yeah, just do whatever you want. If you say your cousin is great, why don’t you invite him over to help you out coding for a week, and we’ll see how it goes.” approach to hiring.
Conclusion
If you put a gun to my head and forced me to summarize my feelings on all of this in a single sentence, it’d be something like this: I am intrigued, but also worried by the ability of technology to facilitate the standardization of social processes or concepts.
If that’s too abstract and you want a basic example, look no further than the classic Falsehoods Programmers Believe About Names. Or in other words, it’s very, very easy for (wrong) assumptions such as ‘Everyone has a first and a last name.’ to end up baked into our technology.
It’s pretty obvious that you’d end up with problems like that, since—no shit, Sherlock—the digital world can at best approximate all of the complexities of reality, you have to drop some complexity somewhere. You’re bound to end up with systems that encode reality imperfectly.
Part of what I’m trying to gesture at here is that the ‘Leetcode interview’ represents a ‘standardized’ component of the modern tech hiring process. It’s pretty easy to see that this ‘standardization’ was only possible due to modern technology (e.g. the internet).
‘Standardization’ is too strong of a word for a bunch of reasons, but that doesn’t keep it from being entirely wrong. It’s enough of a standard that anyone who’s been looking for a job in the industry over the past few years will be familiar with the process.
If you spent some time looking, you’ll find a lot of patterns in modern technology that (kind of) fit into the realm of standardization.
We’re not talking about fully defined, formal standards here. What I’m talking about is pretty banal: For example, I’m talking about the prevalence of ’emoji reactions’ or ‘stickers’ in chat apps. These popped up at some point, and it’s pretty funny to see how Discord, Telegram, WhatsApp, even Signal, and probably multiple others all support both of these features.
Is that weird? I mean, probably not? If users want a feature, it makes sense to add it, right?
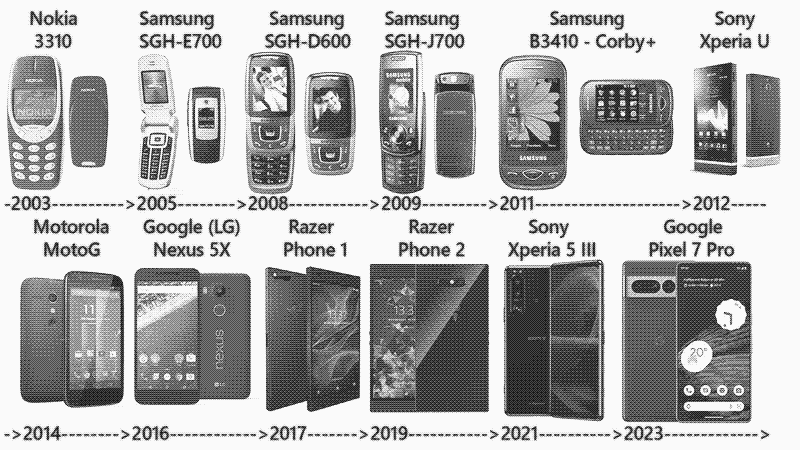
I can’t say that I’ve got a lot of strong opinions about these features specifically, but I really wonder what it means when e.g. Mastodon—more or less—copies Twitter’s user interface and features (scrollable feed, favorites, retweets, following, etc.). Is this a sign that this interface is just that good, or are we inertia-locking ourselves into a pretty narrow design space? (See also, the evolution of modern phones. Early smartphone designs were varied and wild.)
Tying this back to interviews, I think that the shift towards a ’legible’, easy to aggregate and communicate type of hiring process might be more or less inevitable. (At the scale of really large companies, anyway.)
My gut feeling says that this is probably fine, at least in this specific case. I much prefer this world to one in which companies strictly look for your Master’s degree in Computer Science, for example. (At last but not at least since I’m self-taught.)
Anyway. I still find myself coming back thinking about James C. Scott’s Seeing Like a State, but those thoughts will have to wait before I make any attempt at putting them down.
For now I’m back from my vacation, got promoted, and would much prefer to write about something nice and simple.
Like my favorite editor (EDIT: Done!). Or dependency injection, and how I’m still baffled by all the confusion around the term.
We’ll see.
In the meantime, if you liked this article, consider subscribing to my e-mail newsletter or the RSS Feed.