
Let’s talk about a topic that’s either completely obvious or in the “Never heard of any of this” territory, depending on your background.
This is intended to be a fairly pragmatic post for the casual C++ or Rust user trying to understand both languages, or anyone who’s interested in basic type theory. If you’ve ever written code in any statically typed programming language, you’ll understand the code.
A main takeaway of this post is that, first of all, C++ and Rust are significantly different in their approach to type inference and, second, that this has deep, practical consequences.
Also, we’ll have a fun digression about Swift at the end, and talk about how Rust’s approach to type inference basically means that it basically cannot support certain language features.
Before we get there, let’s quickly cover what type inference even is.
What is Type Inference?
Many programming languages have a feature called type inference. Very roughly speaking, type inference allows the compiler to analyze your code and to deduce which type some value or expression should have.
To make sense of that you need to know what a type is, so I guess we might as well cover that:
In an incredibly rare instance of great terminology1, types exist to distinguish between different “types” of values. For example, a number is not the same as “text”, and some arbitrary piece of text isn’t necessarily an e-mail address. A “type” is exactly this information.
Statically typed programming languages (ie. Rust, C++, Go, Java, but not Python or Javascript) require you to explicitly annotate your code with types, and to follow the rules which a given type imposes, otherwise your computer will shout at you and refuse to run your code.
Okay!
Back to type inference:
The most practical consequence of type inference is that you (the humble programmer) don’t need to explicitly write out the type every single time. This would be annoying. Instead, the compiler can figure it out without you. Importantly, the types are still there, you just don’t need to specify them.
For example, here’s how this works in C++:
// we have some function that returns a vector of integers
std::vector<int> get_vector();
int main() {
std::vector<int> v = get_vector();
auto w = get_vector(); // both lines do the same thing
}
Other languages are similar. All that matters is that you have some way to define a variable that doesn’t require you to explicitly spell out the type of that variable.
By using auto you’re saving a total of 12 characters. Wow! This doesn’t sound
like a big deal, but in practice, it is. Not directly because it allows you to save characters, but rather
since it allows the declaration of variables whose types are difficult or impossible to write down.
The classic example is that of the C++ unnamed function, ie. lambda, which has an
unnameable type. To assign a lambda to a variable (without a std::function wrapper)
you have to use auto. In practice, auto also makes it easier to use
values with very long and complex or internal type signatures.
Rust also has type inference, despite not having a dedicated auto keyword. Type inference in
Rust is used basically all the time, and the language also has unnameable type (for example lambdas,
again).
Cool, all of this sounds pretty good.
Except (and this is kind of the point of this article) it turns out that “type inference” in C++ and Rust are completely different, and this has pretty far reaching ramifications.
Differences
Let’s start with C++ and ask Cppreference how this works:
“A placeholder type specifier designates a placeholder type that will be replaced later, typically by deduction from an initializer. … The type of a variable declared using a placeholder type is deduced from its initializer.”
Okay, that’s actually pretty helpful. So in other words, if we write auto foo = ..., then
the type of foo is going to be deduced from the value that’s on the right-hand side of
=.
This is going to sound completely obvious to those of you who are deeply familiar with C++ (or Go, of all languages), and going to sound completely wrong to people whose first statically typed programming language was Rust.
Let me explain. In Rust, the following code compiles2:
fn foo(v: Vec<i32>) {} // defining functions foo and bar that do nothing
fn bar(v: Vec<String>) {}
fn main() {
let x = Vec::new();
let y = Vec::new(); // x and y are initialized exactly the same way
foo(x); // pass Vec<i32>
bar(y); // pass Vec<String> -> x and y have different types!
}
In other words, you cannot deduce the type of a variable just by analyzing the right-hand side of its initialization3. In fact, the compiler is going to look ahead to see how this variable is going to be used, and use that to deduce the type.
People have strong opinions on this feature. Rust users (of course) think that this feature is amazing, while anyone with a C, C++ or Go background might be horrified, for the simple reason that changing a line later in a function can change the behavior of all the code up to that point.
In practice, this isn’t as big of a deal as you might think, and not just because you can trivially specify the exact type which you want if you really need to be sure.
No, the main reason why this isn’t that big of a deal is because the compiler will shout at you if the type is ambiguous or if there’s some sort of contradiction in the type which you’re asking for:
fn bar(v: Vec<String>) {}
fn main() {
let x: Vec<i32> = Vec::new(); // this is a Vec<i32>
bar(x); // ERROR: mismatched types, expected struct `Vec<String>`
let y: Vec<_> = Vec::new(); // this is a Vec. `_` means "I don't care"
bar(y); // pass Vec<String>
let z: Vec<_> = Vec::new(); // ERROR: type annotations needed, cannot infer
// type of the type parameter `T` declared on
// the struct `Vec`
}
Okay, let’s summarize really quickly before we get to the promised ramifications:
C++
C++ barely does “type inference” in a technical sense: What it does have is keywords
(auto, decltype) which are best understood as telling the compiler “Hey, please
replace this specific token with whatever type-specifier that expression spits out.”
This is both true for variable declarations (see above) and for return types, for example:
auto foo() {
return 123;
}
This is also how to think about decltype. Write decltype(expression), and the
compiler will replace that with whatever the type of expression is4. For example:
auto x = foo(); // who knows what type this is?
auto y = bar();
// I have no clue what type `x + y` is, just fill the correct type in
// and then give me some vector that can contain values of that type
std::vector<decltype(x + y)> v = {};
(My understanding is that Rust does not have anything like decltype. There is
some interest, mainly for
obscure macro usage that’s out of the scope of this post.)
Overall the compiler ’looks backwards’. It sees some auto or decltype, then
references all the data it already knows about (ie. the types of values and functions that are already
defined), and uses that to plug in the new type right where it’s needed.5
The way I think about C++ types is like this:
In C++ types “happen” on a line-by-line basis, in an imperative way. After each statement the compiler knows “everything” there is to know up to this point. It knows the types of all values that are in use, and uses this information to deduce how a function call overloads, and how templates get instantiated.
Of course, this is probably vastly incorrect for all sorts of reasons. C++ is complicated, and even learning how C++ resolves function calls can take a few years! But I like to tell myself that it (roughly) points into the right direction. (ie. “The compiler processes code in a certain order. When considering a function call it needs to know the types being passed into it, such that it can figure out how to resolve it ala ad-hoc polymorphism.”).
Essentially, in this model it makes perfect sense that your type checker should never, ever look into “the future” to see how you’re planning to use a value later.
If auto could do that, how would you resolve this sort of code?
auto x = {};
foo(x);
Are you just going to hope that the compiler will figure out the correct type of
x based on what foo is? Could that work? Maybe?
But how do you expect the compiler to figure out which overload of foo will be called? Should
it try all possible types and pick the first one? In which order should this happen? What if there’s also
a bar(x) call in there somewhere? How does this interact with templating? Should it try all
possible template instantiations and try those that compile?
(I’m sure there are better and worse answers to these questions, but I think you can see why, in general, having this feature at all might not be a good idea. Resolving a function call in C++ is complicated enough. Expanding the power of type inference like this would essentially reduce the number of annotations you have to put into your code, in favor of the compiler trying to pick them for you according to arcane compiler rules. I can’t imagine a lot of people would like this idea.)
Templates
Okay, I don’t want to get deep into templates. If you have no experience with templates: Explaining them in detail is out of scope for this post. What matters is that they allow you to write
template<class T>
void fizzer(T val) {
val.fizz();
}
Whenever you call fizzer(foo), it will basically create a copy of fizzer, and
just plug in the type of foo for T (Monomorphization). If the resulting code
doesn’t compile, you get an error. (There’s a lot more to templates to this, but I am focusing on the only
thing that matters here.)
The reason why this matters for the topic of type inference in particular is because in C++,
there is one more place where you’re allowed to put auto. You can use it as a
function parameter type. What this means is that (in C++20) the following is legal:
auto twice(auto x) {
return x + x;
}
This looks pretty scary since it becomes hard to see what sort of value twice should actually
be called with. You need to parse the function body to see that it can be any type with an appropriately
overloaded + operator.
But in practice, everyone who uses C++ knows that this is already the case anyway. That’s just how templates work. It’s called ‘compile-time ducktyping’ for a reason.
My understanding is that the above syntax is nothing but a shorthand for a simple C++ template. In other words, if you use auto like that, the code will just turn into
template<class T>
auto twice(T x) {
return x + x;
}
My understanding is that C++ lambdas essentially work the same way. (It’s complicated.) In practice, this isn’t quite what we mean when we say ’type inference’. The type is already known when you call the function, and templates are just a bespoke way of creating overloads and, reducing code duplication, and letting the compiler ‘fill in the rest’ for you. (So not type inference, just call resolution.)
Full disclosure: This whole section was missing a subsection about Class Template Argument Deduction (CTAD), which I apparently completely forgot existed. So I am adding it now.
Class Template Argument Deduction
It’s pretty complicated, apparently. The ‘simple’ examples are straightforward enough, and get the gist across, let me copy some from CppReference:
std::pair p(2, 4.5); // deduces to std::pair<int, double> p(2, 4.5);
std::tuple t(4, 3, 2.5); // same as auto t = std::make_tuple(4, 3, 2.5);
std::less l; // same as std::less<void> l;
// for Rust-users: this defines a 'templated' struct, generic over some type T
template<class T>
struct A
{
A(T, T) {}; // define the constructor of A
// note how we can pass in two values,
// and both need to have the same type
};
auto y = new A{1, 2}; // allocated type is A<int>
Easy, right? It works just like decltype and auto, by looking at the type of the
values you’re passing into it, right?
That’s what you might believe, until it turns out that C++ has complex deduction rules which make my eyes
glaze over just looking at the description on CppReference. Also, you can define so-called
deduction guides to tell the inference algorithm how to make things work (???).
I am actually slightly baffled by that: I had no idea ‘deduction guides’ were a thing. So, let’s check
them out by crafting an example, and then leaving the topic be, since I have no deep knowledge to add
here. Keep the above example (with A) in mind for this.
template<class T>
struct A
{
A(T, T) {};
};
// error: class template deduction failed
// no matching function for call to `A(int, double)`
// note: deduced conflicting types for parameter 'T' ('int' vs 'double')
auto y = new A{1, 2.0};
Makes perfect sense, right? We’re passing different types, but expect the same, so it errors. If we really want something like this to compile, we can add a deduction guide and tell the compiler what to do.
template<class T, class S>
A(T, S) -> A<S>; // if passed two things with conflicting types, pick the second
auto y = new A{1, 2.0}; // compiles! -> A<double>
auto y = new A{1.0, 2}; // still doesn't compile!
// error: narrowing conversion from 'double' to 'int'
// turns out that 'just pick the second' isn't a good
// deduction guide. who would've thought
The fact that you can tell the compiler how to perform ’type inference’ (or rather, template parameter inference) is pretty crazy to me.
Rust
Back to Rust. Rust is quite different. Rust used so-called Hindley-Milner type inference.
The Rust compiler looks at the code, and sees all of the types and constraints which the language wants it to see, including those that happen “““in the future”””. It’s basically just a giant constraint solver.
Just to reiterate myself on how Rust works here: The compiler then checks whether there are any contradictions (-> compiler error), and whether any type is ambiguous/unknown6 (-> compiler error). If not, all types are uniquely specified, and compilation proceeds.
As a consequence, you can often get away with specifying the “minimal” amount of types in any given function. The compiler will look backwards and ahead, and happily jump around to figure out what you mean. Often you might not have to specify types at all, except at the function boundary:
fn foo() -> i32 { // 1. return value is i32
let mut v = vec![]; // 3. v is of type Vec<i32>
for x in 0..10 { // 5. 0..10 is of type Range<i32>
v.push(x); // 4. x has to be of type i32
}
return v.iter().sum() // 2. the sum of all values in v has to be of type i32
}
In case it’s not clear yet, from the perspective of the developer, this makes a massive difference in how you approach your code.
In Rust typing has a pretty declarative vibe. It’s like working with a proof assistant. Types aren’t processed “line-by-line”, instead there’s a huge interconnected web of beliefs that contains all assumptions which you have about your program, and which only make sense as a whole.
This is also part of what allows Rust to have a single parse function (which, depending on
context, takes a string, parses it, and spits out exactly the type you need, whether that’s an integer
(any type) or even an IP address). No need for stoi, stoul, stof,
etc.
In combination with collect (which essentially converts an Iterator into a
collection in a generic, infered way), this also allows you to write code like this here, where the
function definition is load-bearing:
fn parse_strings_to_ints(v: Vec<&str>) -> Result<Vec<i64>, ParseIntError> {
v.into_iter() // turn vector into iterator
.map(|x| x.parse()) // for each element, parse it into a Result<i64, ParseIntError>
.collect() // aggregate results. if you find an error, return it
}
If you replaced the function declaration with
fn parse_strings_to_ints(v: Vec<&str>) -> Vec<Result<i64, ParseIntError>> { ... }
the above code (on its own) would still compile and, critically, would have drastically different behavior.
This sounds a lot more brittle than C++’s approach to type inference, but in practice it means that every part of your code is capable of “supporting”, and being validated against every other part of your code. It’s not about the compiler ‘guessing’ what you meant, it’s about only having to specify every type exactly once.
Again, contradictions/ambiguity –> error. This is critical for understanding why this works in practice. Mistakes can still slip in, though. All it takes is a situation where two types are substitutable for one another, and this happening by accident while refactoring.
Hindley-Milner Type Inference
Okay, just a few quick facts on what Hindley-Milner type inference is and why it’s interesting and important.
First of all, HMTI is what Rust uses to make its type inference work.7 It’s not the single defining feature of its type system, but it’s a pretty central one. (Which, as far as I can tell, leads fairly naturally to Rust’s trait system.)
Second, what’s interesting is that there are many other languages using it. This list includes Haskell, F#, ML and Ocaml, Elm, Roc. (You might be noticing a pattern here, these are all languages with deep functional roots.) There’s Swift too, and we will get to that (this is foreshadowing for the next section).
In other words, HMTI is specific enough to warrant its own name and Wikipedia entry, but also general enough that it can support many different programming languages.
For a practical example, Rust requires that you specify parameter and return types for each function. It turns out that this isn’t actually required! Haskell performs global type inference across the entire program (adding top-level annotations is considered good style, though).8
Finally, as far as I can tell HMTI isn’t actually that complicated? Based on what I heard it’s not that much of a leap from a “naive” implementation. You might start just going through your whole abstract syntax tree bottom-up and deduce types along the way. The slightly trickier part is that you need to keep track of “holes” or “incomplete types” and fill them in later in a process called “unification”. For example:
let foo: i64 = 0;
return foo + 1;
You know that foo is a 64 signed integer. You consider foo + 1. You know that
1 is a loose Integer type that could “specialize” to different concrete types
such as u8, u16 or i64, but you don’t know its exact type just yet.
Once you go up the tree and consider foo + 1 you use the knowledge that foo is
of type i64, and deduce that 1 also has to be of type i64.
This gives you the type of the return value. At this point this entire snippet has been type-checked. In a
more realistic example, you would check whether i64 matches the return value of the function
which you’re in (and if not, you will return an error).
Generics are handled similarly to the above example. You keep track of holes and fill them in later. A much better summary on how this works (highlighting the roots to logic and constraint solvers) has been written up by Niko Matsakis over at “Baby Steps”.
Really, the main takeaway here is just “Yes, this is literally just a constraint solver and works exactly as you’d implement it yourself, apart from some technical details.”
Literature on type theory has the issue of being full of arcane runes that look like complete gibberish to most people. Even the Wikipedia article on HMTI falls into this trap, for example:
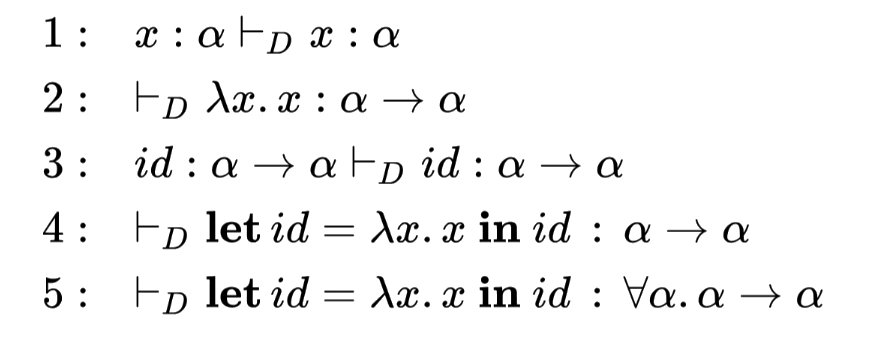
Let’s move on to the interesting part.
Ramifications (and Swift)
A critical piece of knowledge here is that the only reason why Rust’s type inference works is because Rust restricts itself in regard to other features. Here’s some examples:
- There are no function overloads. (Traits sort of represent a way for principled function overloading, but it’s very different from C++ (which just lets you define function overloads however you want). Also, if there’s any ambiguity for the trait that should be picked to dispatch the method, the compiler complains about the ambiguity and you need to specify which function you mean.)
-
There are no implicit conversions.9
In other words, there’s no way for a function call ambiguity to arise because there is a value of type
Athat’s implicitly convertible to values of distinct typesBandC, both of which define a method with the same name. - There is no inheritance. What’s sometimes called “trait inheritance” does not count. Supertraits are just a way to say that “if a struct fulfills trait X, it also needs to fulfill trait Y”.
-
There is no specialization, ie. there is no way to define a “specialized” implementation of a trait (or
function). You can’t say “
Vec<T>has the following implementation ofpush(x), except whenT = int, in which case it uses a different one.” In fact, specialization is one of the famous Rust features that might never ever land due to soundness holes. (Some people are trying to patch the proposal, but others are happy if it never lands since it’d add a lot of complexity and introduce inheritance (sort of) into the language). - There are no duck-typed templates. On the flipside, there are generics, and every generic function can be typechecked purely by looking at its signature. This is what Steve Klabnik coined as Rust’s Golden Rule, and it’s part of why the infamous wall of C++ template instantiation errors doesn’t exist in Rust. I highly recommend you to read his post on the topic if you haven’t already, I found it incredibly insightful.
If you’re paying attention, you’ll see that these features (or their preposterous lack, depending on your perspective) make it fairly easy to resolve function calls in Rust.
When I say “easy”, I’m mainly talking about the ease of reading and understanding the code. Figuring out “which function is being called here?” is a lot easier when the compiler doesn’t have any sort of “Go through this long list of potential candidates, filter out the ones that don’t work, and then pick the best possible one.” approach to function calls.
Assuming we’d want to keep Rust’s “An ambiguous function call should be manually specified by the programmer.” pattern, adding any features that’d increase the risk of (a priori ambiguous) calls would also result in more demands from the compiler to add more annotations (or fully specify function calls).
The alternative is, of course, to start resolving calls more implicitly with (hopefully well-defined) rules that are easy to understand. (I think you can see why this would be a contentious topic.)
That’s the route C++ ended up on, and not entirely by choice. It just sort of grew over the years, had to deal with C’s baggage, and had far fewer examples to look at and grow from. Inheritance is a natural idea, so are function overloads and implicit conversions.
Give it a few years, and you end up with really complex rules to resolve anything at all.
I hope that (at this point) it’s very clear to you that C++ and Rust are (in a lot of ways) basically incompatible insofar as a lot of these semantics go. And (importantly) that this incompatibility is deeply rooted in their respective type systems.
Before we wrap things up, let’s take a quick look at Swift. It’s going to be funny, I promise. At least if you aren’t in on the joke yet.
A fun little digression
Let’s imagine we’re building a programming language and (human and foolish as we are) decide to add all sorts of fun features to our language: Function overloading, inheritance, and so on. And while we’re at it, let’s imagine we’re in the process of discussing a new feature: An integer literal should be able to express user-defined types.
For example, they might define a type Foo which can then be defined and used as in this
example:
let foo: Foo = 123;
// or, if you prefer C++-style variable declarations
Foo bar = 123;
// and to upset everyone
return foo + bar + 456;
Pause for a moment. Does that proposal sound weird to you? (It probably does, but let’s just go with it.
Besides, there’s some legitimate usecases here, such as making the standard library less “special” and
supporting obscure architectures using types such as i36 which surely exist
somewhere.)
Well, it’s just a literal value. How bad can it be, right? When those are used, their types are always obvious through context, right?
It turns out that “simple” features like this can get you into murky water faster than you’d expect, and have far, far reaching consequences. Consider the following expression:
let a: Double = -(1 + 2) + -(3 + 4) + -(5)
I guess some of you saw this “big reveal” coming from a long time ago, and not just because other people covered it already, but here goes:
Trying to compile the above expression in Apple’s flagship programming language Swift nets you a “the compiler is unable to type-check this expression in reasonable time” error.
Yes, really. This expression is just too complex for the compiler. At least at the time of writing this.
Mandatory disclaimer: I have approximately zero experience with the Swift programming language, so I cannot say how much of a problem this is in practice. I stumbled over this while doing research on this post and found it too fascinating not to share. Mainly for the (hopefully fairly obvious?) reason that Swift’s type system makes exactly the mistakes–sorry, “tradeoffs”–I built up in the paragraphs above.
In other word, it awkwardly tries to bridge the gap between Rust’s functional type inference and pragmatism, and ends up shooting itself in the foot pretty badly. I say pretty badly since it looks as though people are running into performance issues with Swift’s type checker in practice, so this isn’t just a theoretical concern. (No wonder, looking at the expression above.)
My understanding is the following:
- First of all: Yes, the Swift compiler is in fact unable to type-check completely trivial-looking expressions.
- This problem has existed for many years, and solving it completely is probably impossible.
- You could probably get pragmatic improvements for some cases by hard-coding special rules for standard library types, but that’s unappealing for a language such as Swift which (as far as I know) really doesn’t want to give its own standard library types a lot of special treatment.
- All of this is due to combinatorial explosion.
-
The literals are pretty critical to this example, I think. Swift has a protocol (interface/trait) called
ExpressibleByIntegerLiteral. A lot of types fulfill it.
For more examples and a technical discussion on where this goes wrong, please read this post by Matt Gallagher. It’s from 2016, so who knows how much changed, but I found it quite interesting.
So yes, you combine Hindley-Milner type inference with a feature that sort of looks a bit like implicit conversion and some funky operator dispatch, and you suddenly end up with a type checker that runs in exponential time complexity and there’s nothing you can do about it.
It’s fun how programming languages work, right?
Conclusions
Anyway!
If you made it all the way to this point, thank you.
This was intended to be a lot shorter than it turned out to be.
My feeling is that literally everything above is indicative of a trade-off pattern.
If you want to have a fancy, bespoke modern type checker with Hindley-Milner type inference semantics, you need to accept one of the following:
- Bad performance for your type checker with a risk of exponential blow-up.10
- No features that look anything like “the compiler picks the best option out of several ones”. No function overloading, implicit conversions, etc.
It should be pretty clear how Rust, Swift and C++ map to the available options here. It should also be pretty clear that adding HMTI to C++ would be a disaster, and that Rust just fundamentally cannot support certain features C++ has.
Or in other words, Rust and C++ aren’t nearly as similar to each other as you would think when reading that “Rust is C++ but with safe borrow checking semantics™.” somewhere online for the x-th time.
Taking a step back from the concrete, pragmatic questions of Rust and C++, after writing all of this my gut feeling tells me that the whole “The compiler picks the best option out of several available ones.” pattern is just not a good way to design a modern programming language.
It’s fine if all of the available options are strictly equivalent (for example, picking the best option of generating lower level code is literally the job of an optimizing compiler), but if they are not then you quickly get into all sorts of trouble, and you force the programmer to keep track of the exact algorithm the compiler uses to “pick”. (Python’s Method Resolution Order for multiple inheritance is a good example.)
Maybe I just have terminal Rust-brain, but “The language allows you to explicitly and relatively easily specify everything, and the compiler shouts at you if there’s any ambiguities, and you have to clarify.” just seems like a much less confusing (for humans, the compiler, and tooling) way to design a language.
Just like, have the human specify exactly what they want, and make the specifying part easy.
This is less about the whole ‘performance’ thing and more just about plain readability, of course.
Maybe I’ll write a follow-up on this someday.
But really, what do I know!
Honestly, this type theory stuff gets complicated.
It turns out that people are still discovering new algorithms that allow both a Hindley-Milner type system and certain local-ambiguousness-enhancing features to coexist (with a usually reasonably efficient inference algorithm).
If you really want to go down that rabbit hole (I don’t, for the time being) start with reading Stephan Dolan’s thesis or something. It introduces an extension of HMTI capable of handling subtyping, or something like that. I can’t help you beyond this point. Just be warned that these fancy features probably depend on some highly technical details.
I don’t want to trip over my feet and say something wrong, so I’ll leave it at that.
Or rather, I’ll leave you with one final plea:
If you’re a C++ enjoyer or Rust-fan and ever get into fights about programming languages online, remember that there are a lot of discussions that could be had. Discussions which are not just about safety or syntax. (I think most of us are tired of those at this point.)
Why not argue about type inference the next time?
Or maybe complain about the lack of decltype in Rust?
Or have a viscious fight over how the lack of specialization leaves a lot of performance on the table in idiomatic code?
Or argue how, even if specialization will be added to the language, this might result in a loosening of Rust’s design goals and add harder-to-reason-about implicit function call dispatch to the language?
The possibilities are, well, not exactly boundless, but definitely broader than comment sections would suggest.